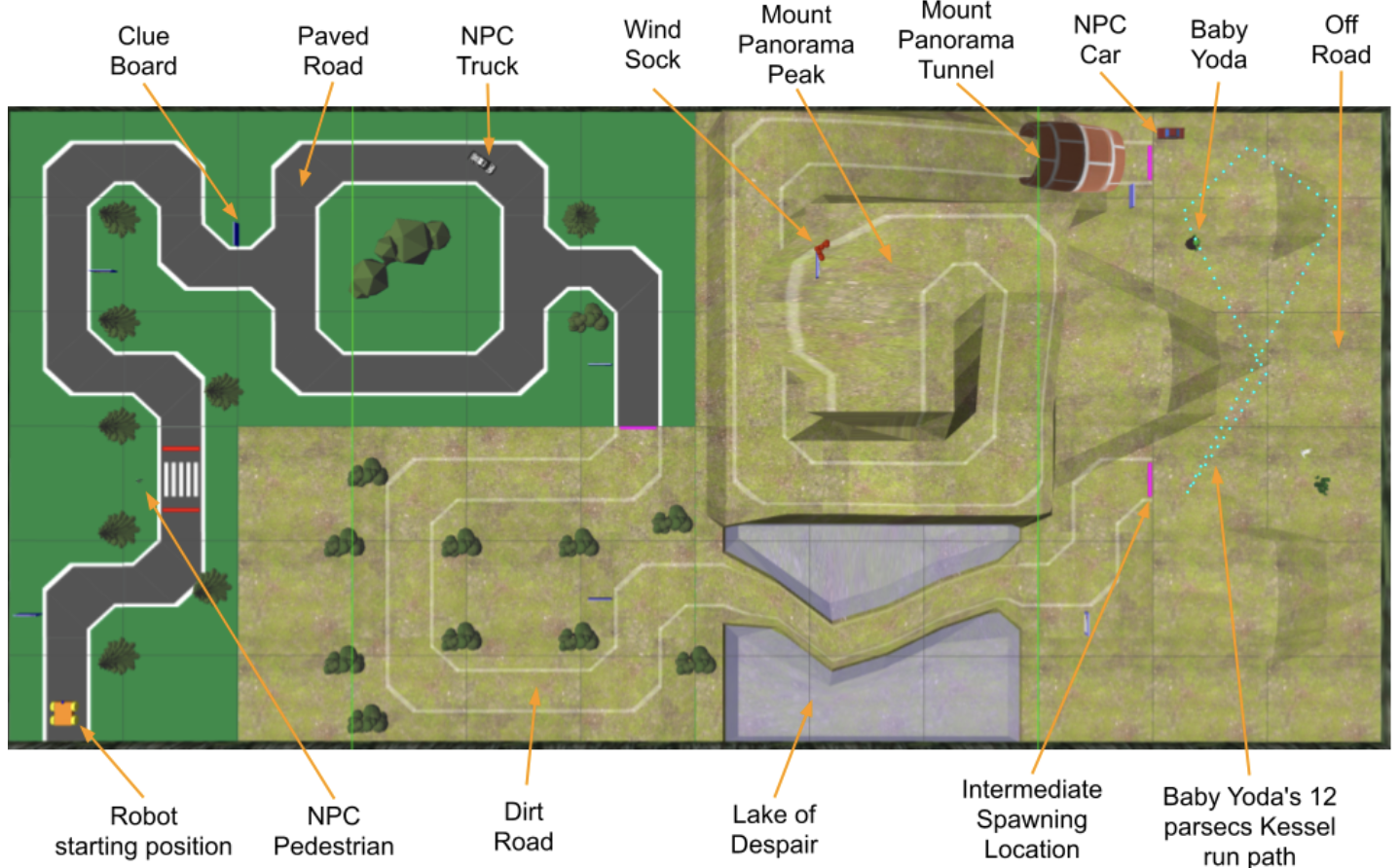
Project Overview
For ENPH 353, my partner George and I built “HTTP 418”—a control system for an autonomous clue-finding robot operating in a Gazebo simulation. The robot’s goal was to navigate a course while reading clues from signboards, avoiding pedestrians and vehicles, all using only its onboard camera. The project culminated in a competition where robots raced to collect all clues correctly.
Full Report PDF | GitHub Repository
System Architecture
The control system is built as a collection of ROS nodes connected by topics and services. This decoupled architecture allowed us to test components individually and handle varying compute constraints—the steering model runs at camera FPS while the YOLO OCR model runs on cloud GPUs.

The core components:
- inference_node: Drives the robot using an ONNX model trained via imitation learning
- clue_detector_node: Finds blue signs via HSV filtering and sends crops to a Modal-hosted YOLO service
- pedestrian_tracker_node: Uses YOLO12n for pedestrian and vehicle detection
- clue_collector_node: Aggregates OCR results using histogram voting
- crash_detector_node: Monitors for stuck states and teleports the robot to recover
Sign Recognition with YOLO
Rather than training a traditional CNN for OCR, we repurposed YOLO to detect individual characters. The idea was to get one model to handle everything: signs, letters, pedestrians, and vehicles.
Cloud Training
Training YOLO locally was painfully slow. We rented a Runpod instance with four RTX 5090s, which let us iterate through models in hours instead of days. With ~100 GiB of synthetic training data, we could train a large YOLO model to near-convergence overnight.

Classical Sign Detection
YOLO struggled to detect the blue sign borders reliably, even though it excelled at character recognition. We fell back to HSV thresholding to find signs—the blue border has a unique color that doesn’t appear elsewhere on the map.

Once we found a sign, we’d crop it and feed just that region to YOLO for OCR. This hybrid approach worked much better than end-to-end YOLO detection.
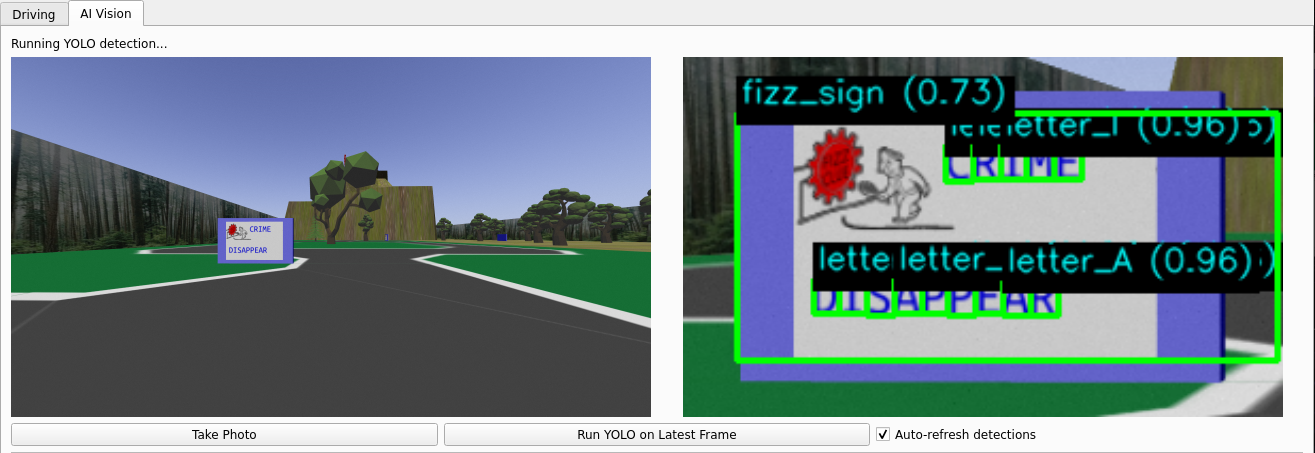
Modal Endpoint for Inference
Since OCR could be decoupled from the simulation, we deployed our YOLO model on Modal’s serverless GPUs. The robot would stream images over the network, and Modal would auto-scale to process them. This let us get 20-30 OCR predictions per sign, even when driving fast.
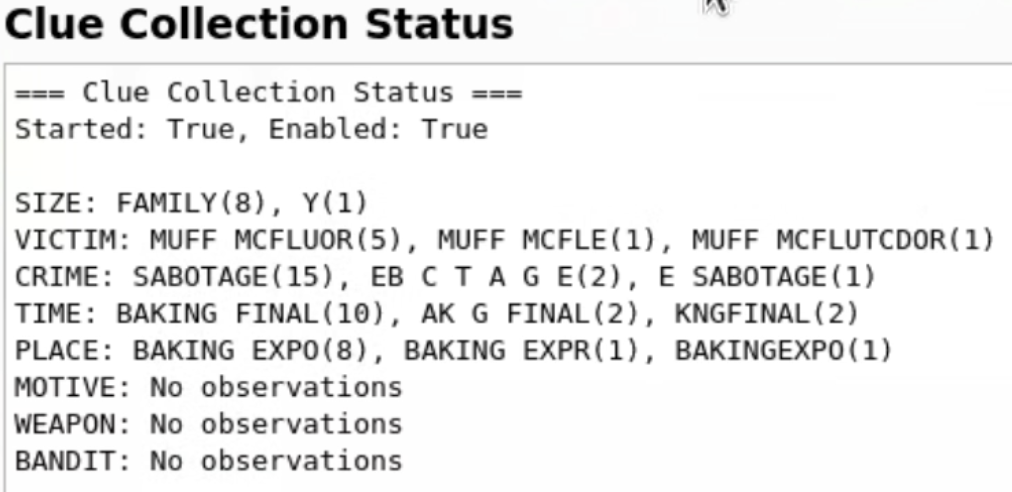
Histogram Voting
With many predictions per sign, we needed a way to pick the correct one. The clue_collector_node maintains a histogram for each clue type, and every 2 seconds publishes the most frequently observed value. This simple majority-vote approach handled OCR errors gracefully.
Line Following: RL vs IL
Reinforcement Learning Attempts
My first instinct was to use reinforcement learning. I tried DQN, Double DQN, SAC, and PPO with various reward functions based on progress toward waypoints.
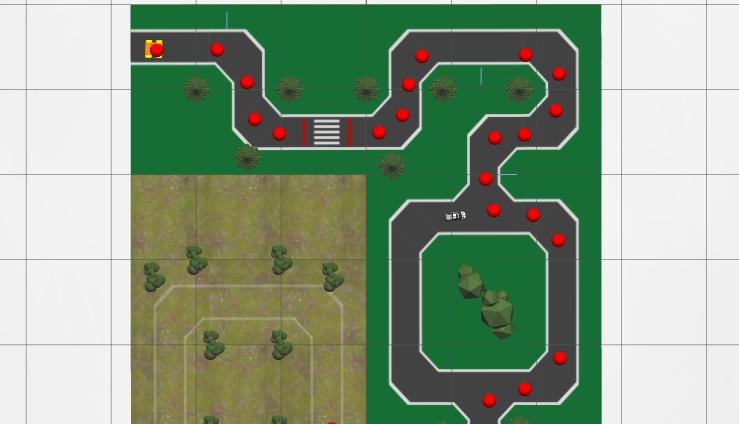
The PPO implementation with RLlib showed the most promise—the model did learn to follow the line in limited scenarios:
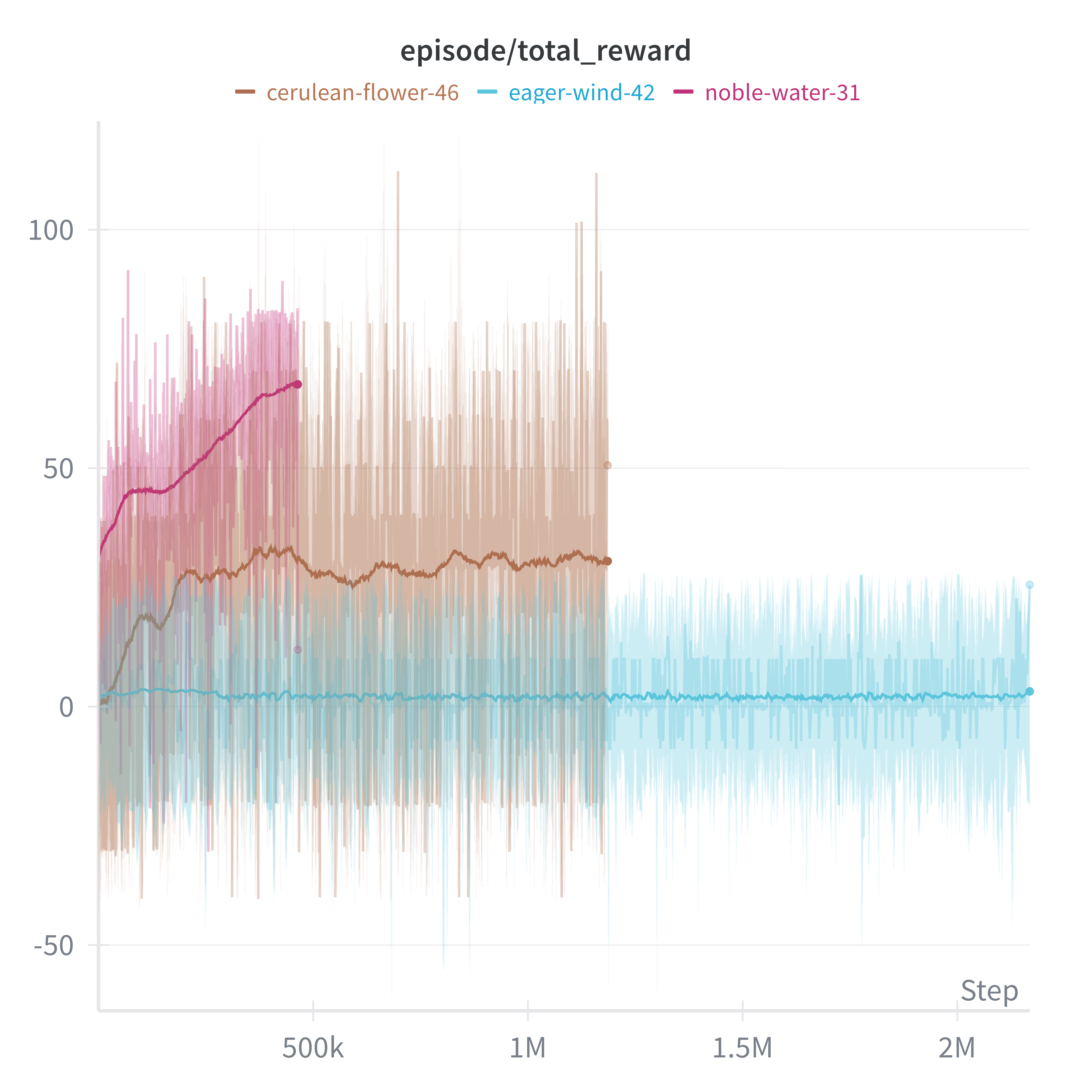
But convergence times were brutal: 48-72 hours per configuration. With only days until competition, RL wasn’t going to work. The fundamental bottleneck was compute—Gazebo’s real-time factor on my laptop meant every second of training took two seconds of wall clock time.
Imitation Learning
We switched to imitation learning, where the robot learns by mimicking human demonstrations. I built a data collection GUI where I could drive the course with arrow keys while recording frames and steering values.
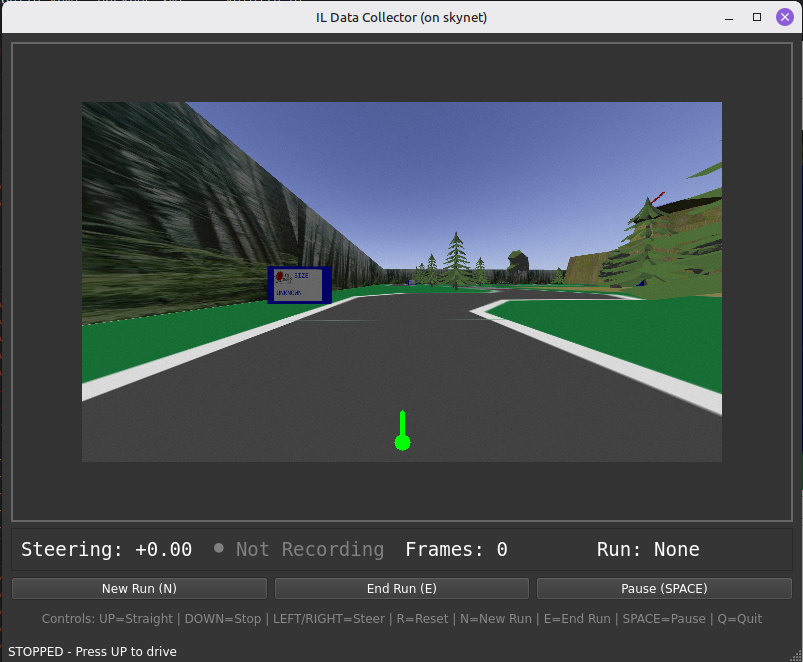
The key insight was using smooth interpolation on keyboard inputs. When you press left/right, the target steering moves to -1 or +1, but the actual value interpolates smoothly. This gives continuous labels from discrete inputs, preventing jerky behavior.
Our model architecture was based on NVIDIA’s end-to-end learning paper: convolutional layers to reduce spatial dimensions, followed by dense layers, with a tanh output for steering in [-1, 1]. After about an hour of training on ~30k frames, the model could follow the line reliably.
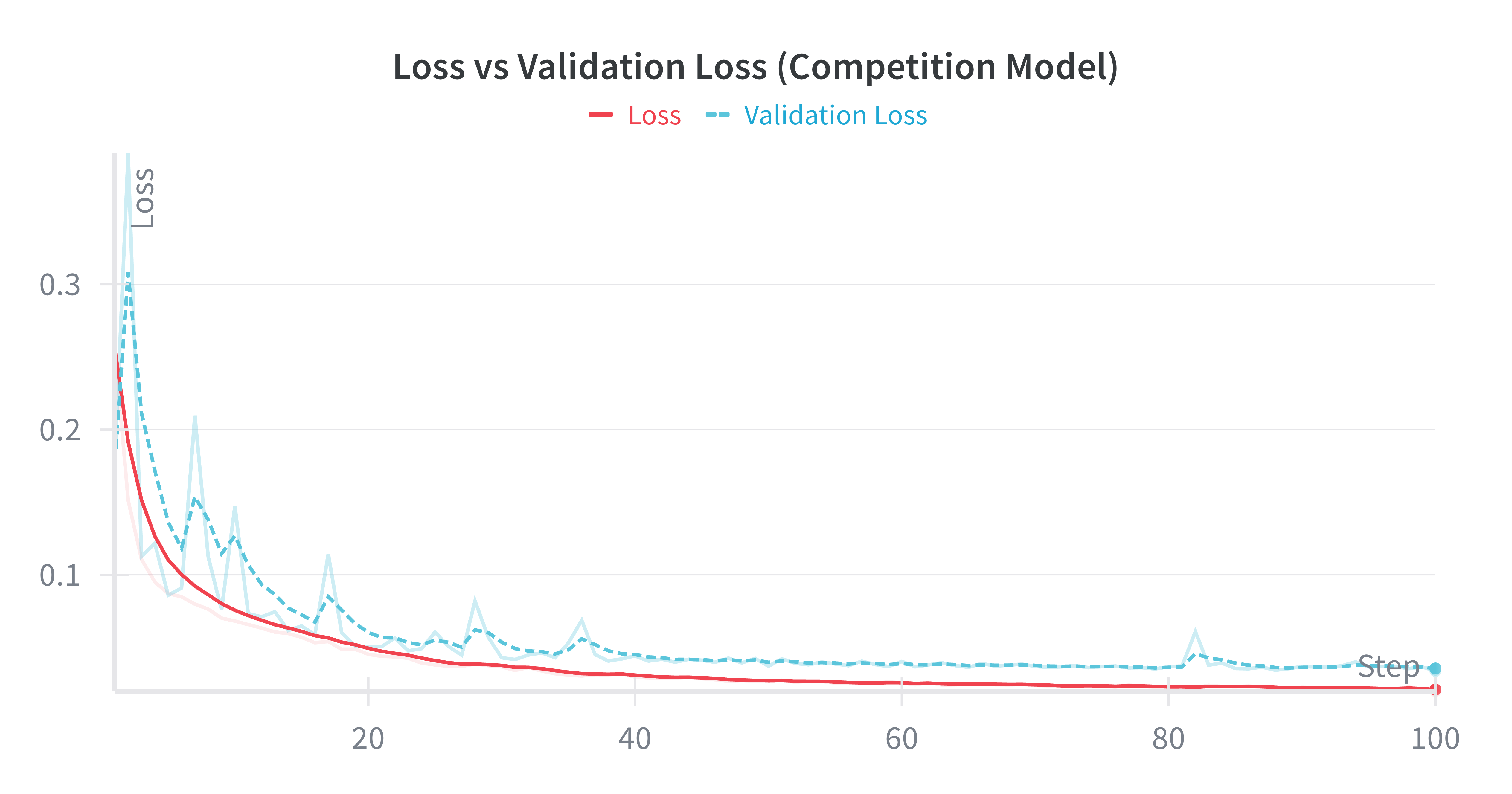
We exported to ONNX format to decouple training (modern Python/TensorFlow) from deployment (ROS’s older Python environment).
Results and Issues at Competition
The YOLO OCR performed well when it worked. The confusion matrix shows strong diagonal performance across characters:
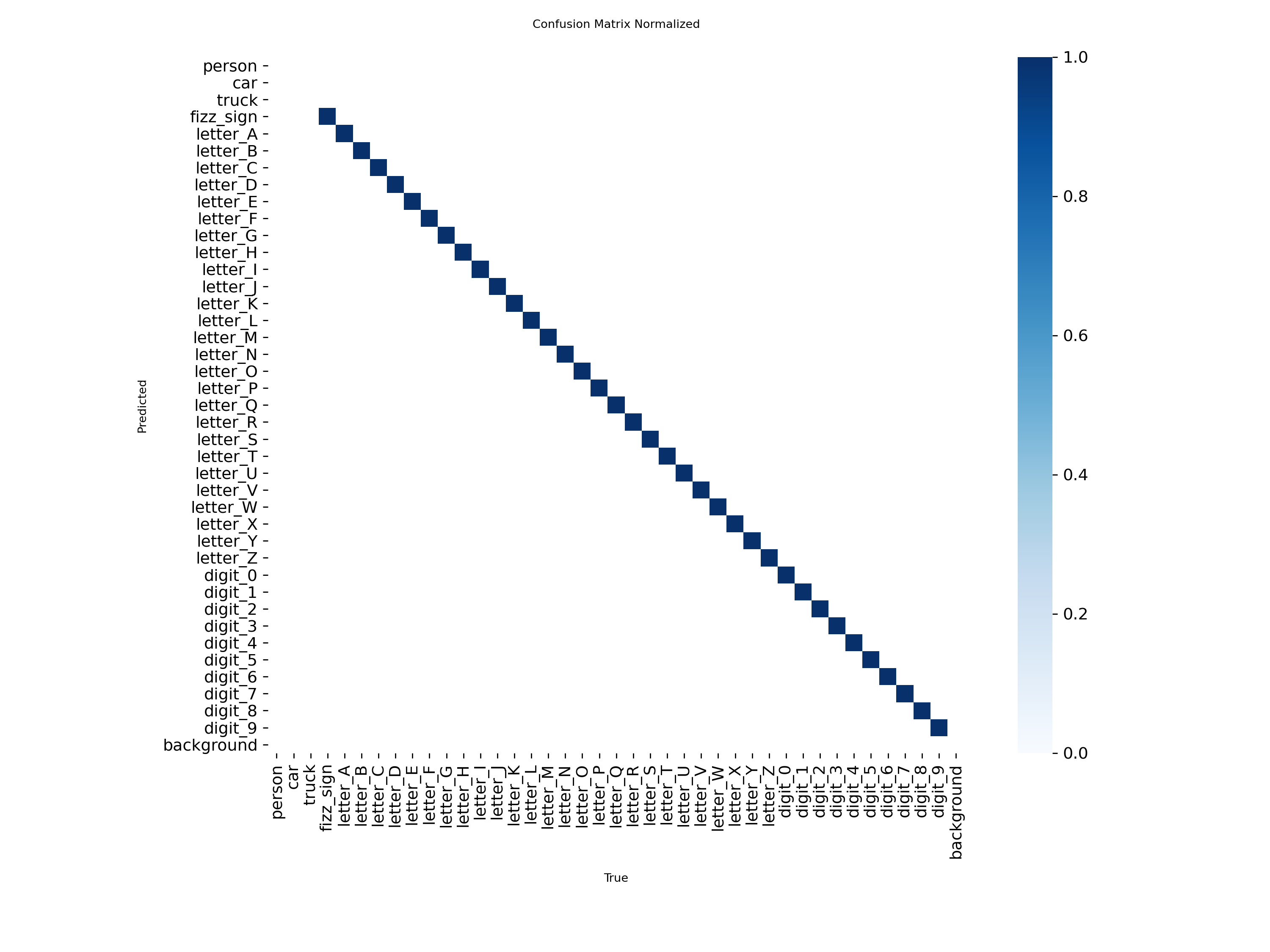
However, we discovered the day before competition that numbers would be in the clue bank—and our model wasn’t trained on them. We hastily retrained but accidentally deployed the old model.
The bigger issue was a respawn logic bug. We’d added logic to respawn at the parked truck if the robot fell into the water after reading early signs. But this reset the crosswalk detection state, causing the robot to wait indefinitely in the tunnel for a pedestrian that didn’t exist.
Lessons Learned
- IL » RL for limited time: Imitation learning converged in hours where RL took days. For time-constrained projects, human demonstrations are incredibly data-efficient.
- Cloud compute is cheap: A quad-5090 machine costs a few dollars per hour. Don’t suffer with slow local training.
- Hybrid approaches work: YOLO for characters + HSV for sign borders outperformed end-to-end YOLO.
- Test your deployment artifacts: We deployed a model without the classes we needed. Always verify what’s actually running.
- Edge cases in state machines kill you: The respawn-crosswalk interaction bug cost us the competition.
Division of Labor
I focused on driving (both RL attempts and IL), the system architecture, and the YOLO OCR approach. George handled character recognition model training and IL data collection/tuning. We both worked on the networking setup for competition, which involved cloud compute, home servers, Tailscale VPNs, and even Bluetooth speakers for our celebration music server.
For complete technical details, model architectures, and additional results, see the full report.